
As more and more companies apply best practices in website tracking, the use of tag management systems and the data layer have become fairly widespread.
But while many websites that use tag management have a data layer by default, the extent to which companies utilize this data layer could still see some improvement.
For those who aren’t familiar with the data layer or are looking to better utilize this important resource, read on.
What Is the Data Layer? A Definition
Data Evangelist Justin Cutroni concisely defined the data layer (alternatively called a “digital data layer”) as follows:
“A data layer is a JavaScript variable or object that holds all the information you want to collect in some other tool, like a web analytics tool.”
If you’re not familiar with web programming, a JavaScript variable is like a bin that you can store data in for retrieval later. Here’s an example of what a basic data layer object might look like:
Data Layer Example
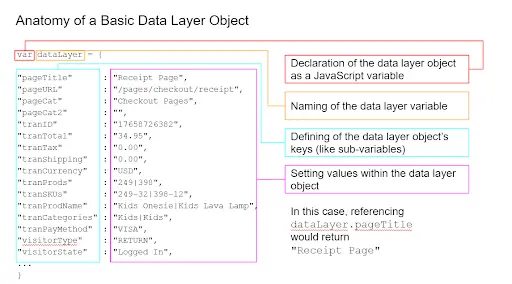
Your data layer will look different depending on your specs and your tag management system (for example, the default dataLayer object in Google Tag Manager is an array instead of an object). Regardless of specifics, the end result is the same: a repository to hold data that other tools can reference.
Benefits of the Data Layer
For websites who do not utilize their data layer, the alternative is to have each marketing and analytics vendor capture its own data instead of referencing the data layer. Having each vendor capture its own data is problematic because:
- These variables only apply to one vendor. That means you would need to have a process of variable declaration and population for each and every marketing technology. Repeating this process is redundant.
- Each marketing technology will have slightly different definitions of user events. As a result, the data they collect may be inconsistent across your Martech stack.
- Deploying separate code for each vendor will slow down your website.
The data layer helps protect against these issues:
- The variables are vendor-agnostic. You only have to deploy this once and then delineate within your third-party tool which variable corresponds with each metric.
- Using a data layer allows you to standardize data definitions because data is only gathered once.
- Gathering then distributing data via a data layer is faster than having each tool gather data on their own.
What Does the Data Layer Have To Do with Web Analytics
The primary benefit of a data layer is that it expedites and standardizes the data collection process by gathering data into one central location and then redistributing it to your various marketing technologies.
Looking at the above data layer, you can see that several of the data points within that object could be useful for analytics, such as transaction totals and product IDs. If you’ve properly implemented your data layer, then your analytics solution should be able to easily reference it for the appropriate data.
Different ways do exist that your analytics solution could otherwise capture the data it needs (such as through DOM scraping). Still, the cleanest way to pass data from your back-end systems to your various marketing & analytics vendors is through a data layer, first because doing so will ensure data is consistent from vendor to vendor, and second because centralizing then distributing data is faster than having each vendor capture data on its own.
Why DOM scraping is an issue
DOM-scraping is a method in which marketing tags collect values from the Document Object Model (DOM)—the HTML structure—using JavaScript selectors (tag names, ids, classes, and paths).
For example, a marketing tag could use JavaScript or jQuery to pull the value from a form field and assign it to a variable:
HTML:
<form><input id=’form-field’/></form>
JAVASCRIPT:
<script>s.pageName = document.getElementByID(‘form-field’).value;</script>
DOM-scraping can be handy, because as long as a website’s HTML elements are well identified, values can be easily gathered from a page with some basic knowledge of JavaScript.
But DOM-scraping is also problematic. If website structure changes due to a redesign or new release, then analytics scripts that rely on JavaScript selectors for DOM-scraping may no longer be able to pull the correct values into your variables.
The data layer, on the other hand, is built separately from the DOM, using a combination of three methods:
1. Hard-coding variable values. Variables and values that don’t need to be dynamic can be hard-coded into the data layer.
2. Back-end variable population. When using a template-based CMS, values can be pushed from the CMS database into the data layer as the page is being built.
3. Front-end variable population. Using event listeners like onclick within HTML tags allows you to push values into the data layer when an event occurs:
<button id=’button1′ onclick=’dataLayer.push({‘event’: ‘button1-click’})’ />
*Note: Front-end variable population may just seem like DOM-scraping in reverse, pushing data instead of scraping data. The difference here is that event listeners are less likely to change compared to an HTML element’s id, classes, and paths, which JavaScript selectors rely on. As long as your company establishes protocol around pushing events into the data layer, the marketing technologies will always have the data they need.
A Checklist for Data Layer Implementation
Below are some basic topics that will need to be discussed among the developers, marketers, and other stakeholders:
- Decide on data layer structure and naming conventions (see blog post).
- Develop and deploy code to populate the key-value pairs (hard-code, back-end, or front-end).
- Remove any vendor-specific DOM-scraping or other data gathering from your website pages, templates, or header.
- Update variable documentation, mapping your data layer elements to business/vendor requirements.
- Perform regular audits to verify that your data layer is functioning as expected.
Auditing Your Data Layer
After you implement your data layer, remember that it doesn’t exist in a vacuum. A website is a highly volatile environment, and resources like the data layer and marketing tags are subject to change and even interference from other technologies installed on the site. All too often, one team will make a change to a site that inadvertently affects someone else’s tracking.
As such, a comprehensive audit of your data layer is an important activity that you should carry out frequently.
If you deploy an enterprise-grade data layer, a manual audit may not be realistic, in which case a solution like ObservePoint’s Technology Governance is highly useful.
If you want to see a custom audit of your own site testing the data layer and your various marketing tags, request a demo.
Related Posts

ObservePoint and AI: Using AI to help you innovate with ObservePoint

Top News from IAPP Global Privacy Summit 2024

How to Interpret an Audit Report

Getting to Know the ObservePoint Audit Report

ObservePoint + NP Digital: How Digital Marketers Should Prepare for 3rd-Party Cookie Deprecation
Does Your Site Work Without 3rd-Party Cookies?
ObservePoint and AI: Using AI to help you innovate with ObservePoint
Top News from IAPP Global Privacy Summit 2024
How to Interpret an Audit Report
Getting to Know the ObservePoint Audit Report
ObservePoint + NP Digital: How Digital Marketers Should Prepare for 3rd-Party Cookie Deprecation